前言
这几天比较火的一个超轻量 TTS 模型,「Model size less than 25MB」,实属是有些惊人了,并且不需要GPU,用 CPU 即可以完成推理,在边缘设备上都可以使用,比如手机、树莓派等等,贴上官方 repo。

使用
目前官方给出的还是 nano-0.1 版本,借鉴 1 和 2 做了个 demo,访问下面链接可以使用,有八种音色可以选。
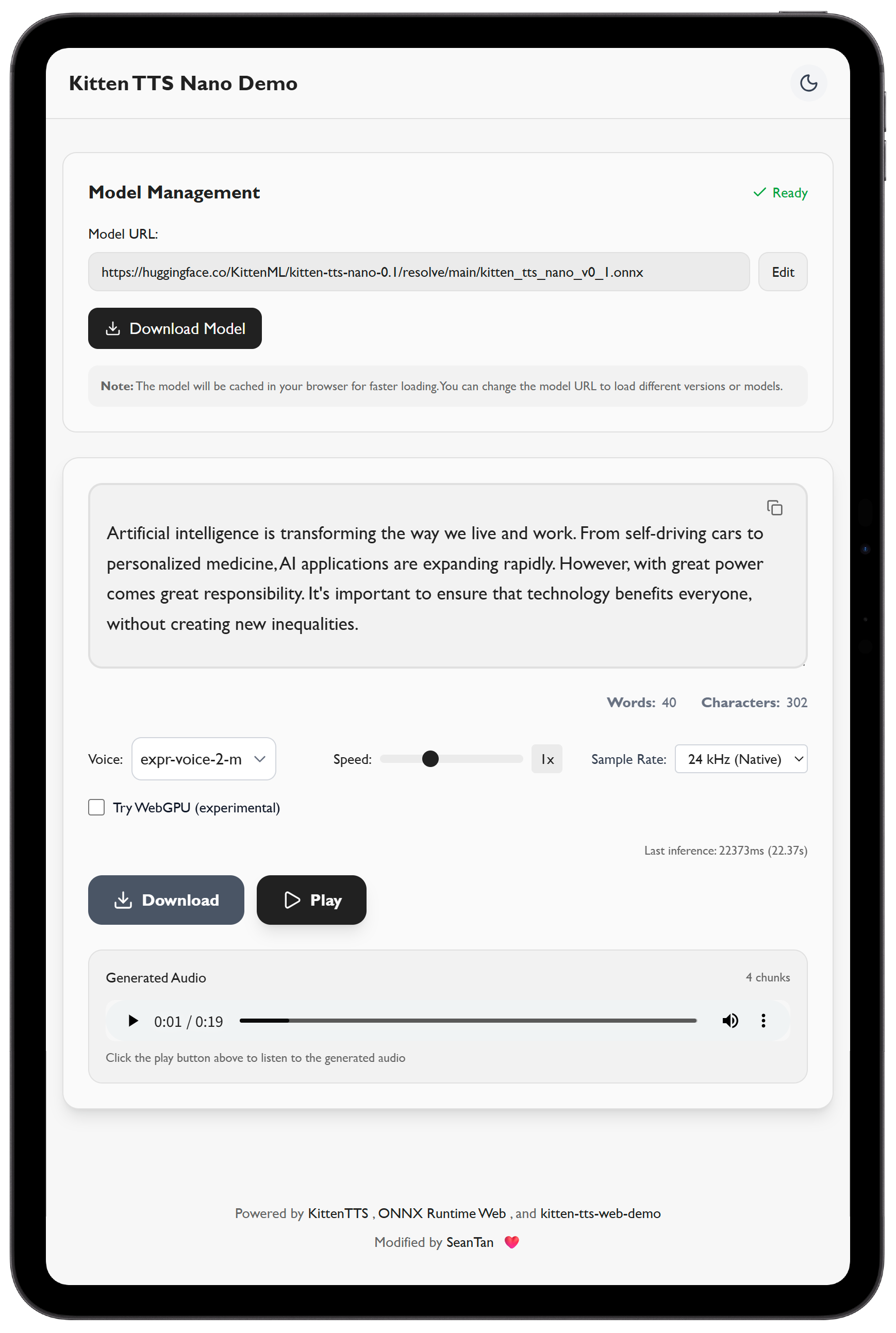
Demo 从 HuggingFace 动态下载 Kitten TTS Nano-0.13模型,并使用 ONNX Runtime 4在 Web 端执行推理结合选定的声音 embedding。
也可以直接使用 Python 调用,下面给出示例代码 5,使用 Colab CPU,Python 调用默认音色是:expr-voice-5-m。
https://colab.research.google.com/drive/1sbglAac41Lg1NaQBxYLLmpGoO1cZ7WtC?usp=sharing
推理速度还是很快的,尝试了两个句子的推理:
This high quality TTS model works without a GPU --> 8秒完成推理
Now enter Kitten TTS. It’s tiny. Like, 15 million parameters tiny. That’s not just smaller than anything else you’ve seen it’s the smallest decent-sounding TTS out there. Less than 25MB total. Doesn’t need a GPU. Doesn’t even care what machine it’s running on. Your laptop, a Raspberry Pi, probably even a potato with a USB port. --> 24秒完成推理
但说实话,这个模型输出的声音有很多软失真,扬声器有点沙沙的声音,某些音色这个问题会减弱一点,音频质量不及官方给出视频中的质量,似乎是因为现阶段给出的 nano-0.1 模型与视频中的模型有出入,官方回应后续会更新模型,但仍是「超轻量」模型。但综合来说在 25M 这个模型大小中,表现得还可以,期待后续模型的更新。
总结
引用 Reddit 评论6中的作者回复,"local voice ai is the future",不是每个人都有 GPU,较小的成本可以实现不错的效果,何乐而不为。
Tips
目前该版本的模型仅支持英文。
The current version of the model only supports English.
2025.08.20 模型已更新到 kitten-tts-nano-0.2,demo 已做更新,在demo模型选择界面可选择最新模型。
The model has been updated to kitten-tts-nano-0.2, and the demo has been updated accordingly. The latest model can be selected in the demo model selection interface.
2026.05.03 更新。 模型已升级至 KittenTTS v0.8 系列,现提供三个模型可选:
- Nano v0.8 (15M 参数, ~24MB) — 最快,推荐日常使用
- Micro v0.8 (40M 参数, ~41MB) — 质量与速度均衡
- Mini v0.8 (80M 参数, ~78MB) — 最高质量
音色已全部更新为具名音色,替代了旧版的编号式名称:
| 旧名称 (v0.1/v0.2) | 新名称 (v0.8) |
|---|---|
| expr-voice-2-f | Bella |
| expr-voice-2-m | Jasper |
| expr-voice-3-f | Luna |
| expr-voice-3-m | Bruno |
| expr-voice-4-f | Rosie |
| expr-voice-4-m | Hugo |
| expr-voice-5-f | Kiki |
| expr-voice-5-m | Leo |
参考
Chris Clower - https://clowerweb.github.io/kitten-tts-web-demo/↩
HuggingFace-kittentts-model - https://huggingface.co/KittenML/kitten-tts-nano-0.1↩
ONNX Runtime - https://onnxruntime.ai/↩
Reddit _kitten_tts_sota_supertiny_tts_model_less_than_25 - https://www.reddit.com/r/LocalLLaMA/comments/1mhyzp7/kitten_tts_sota_supertiny_tts_model_less_than_25/↩